Different Machine Learning Algorithms for Data Science

Machine Learning is a study that offers computers and systems the capability to learn independently without explicit programming. For example, let us say you have a newly installed shopping application, and the first search of yours is about some books, and then when you log in for the second time, the home screen displays different new book collections you may be interested in. No one has programmed that application to show you the products you have searched for; it is because machine-learned and acclimated. How will the machine adapt to the user? Simple! by using the data. In this example, books are given as data to the application. The application displayed the things (new book collections) you may be interested in checking because of this data. And this process is called Machine Learning.
In the first picture, you can see searching for books, and the second picture shows how the application’s homepage is displayed based on your interest.
In simple words, as an application of artificial intelligence (AI), Machine Learning allows systems to learn from experience without any explicit programming. Machine Learning focuses on creating computer programs with the capability of learning on their own by accessing data.
Different categories of Machine Learning algorithms for data science
Supervised learning: Supervised learning is a subcategory of Machine Learning and Artificial Intelligence. The goal of supervised learning is to increase the accuracy of your predictions. In machine learning, labeled datasets can be used to train algorithms for classification or prediction.
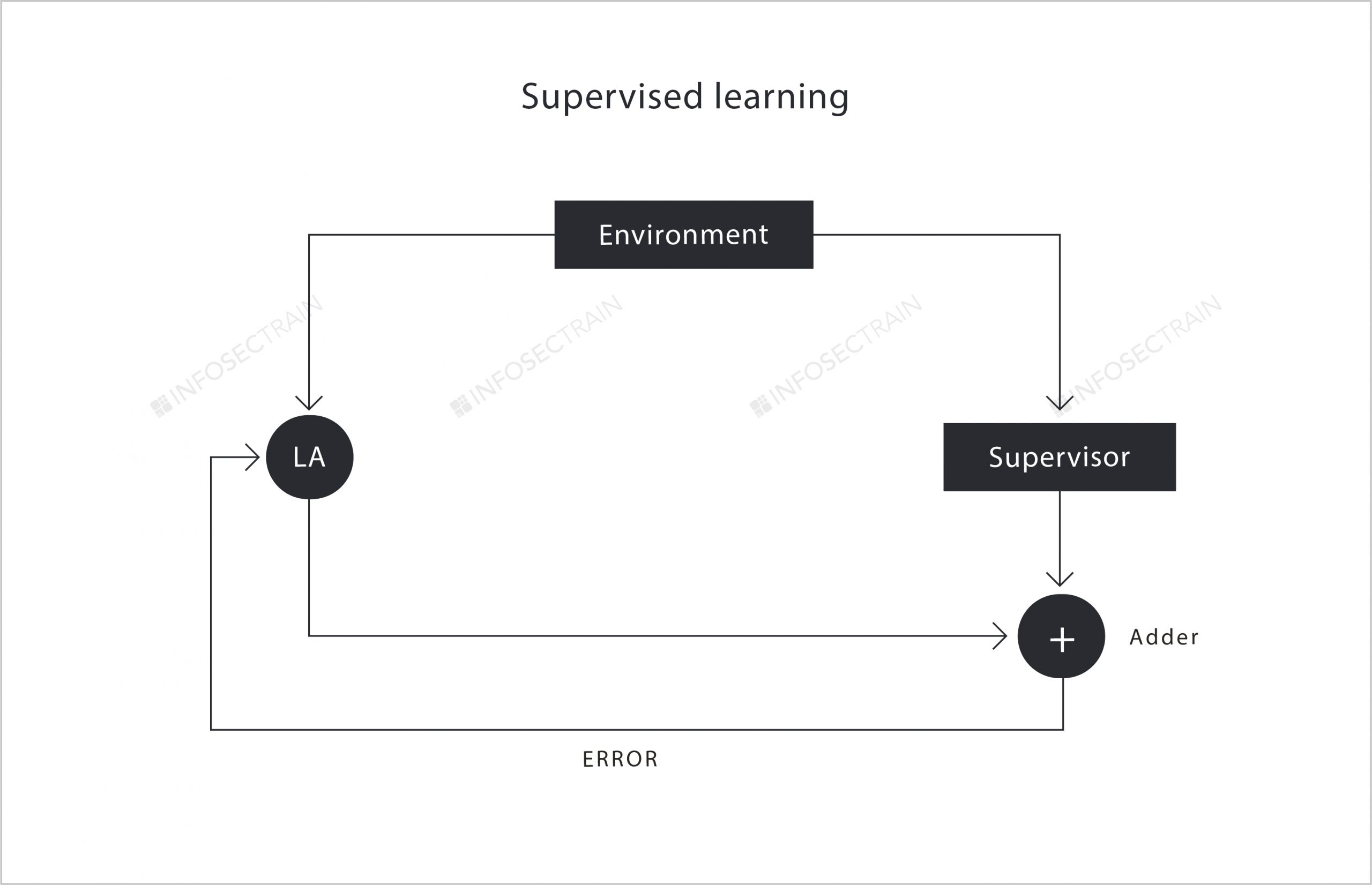
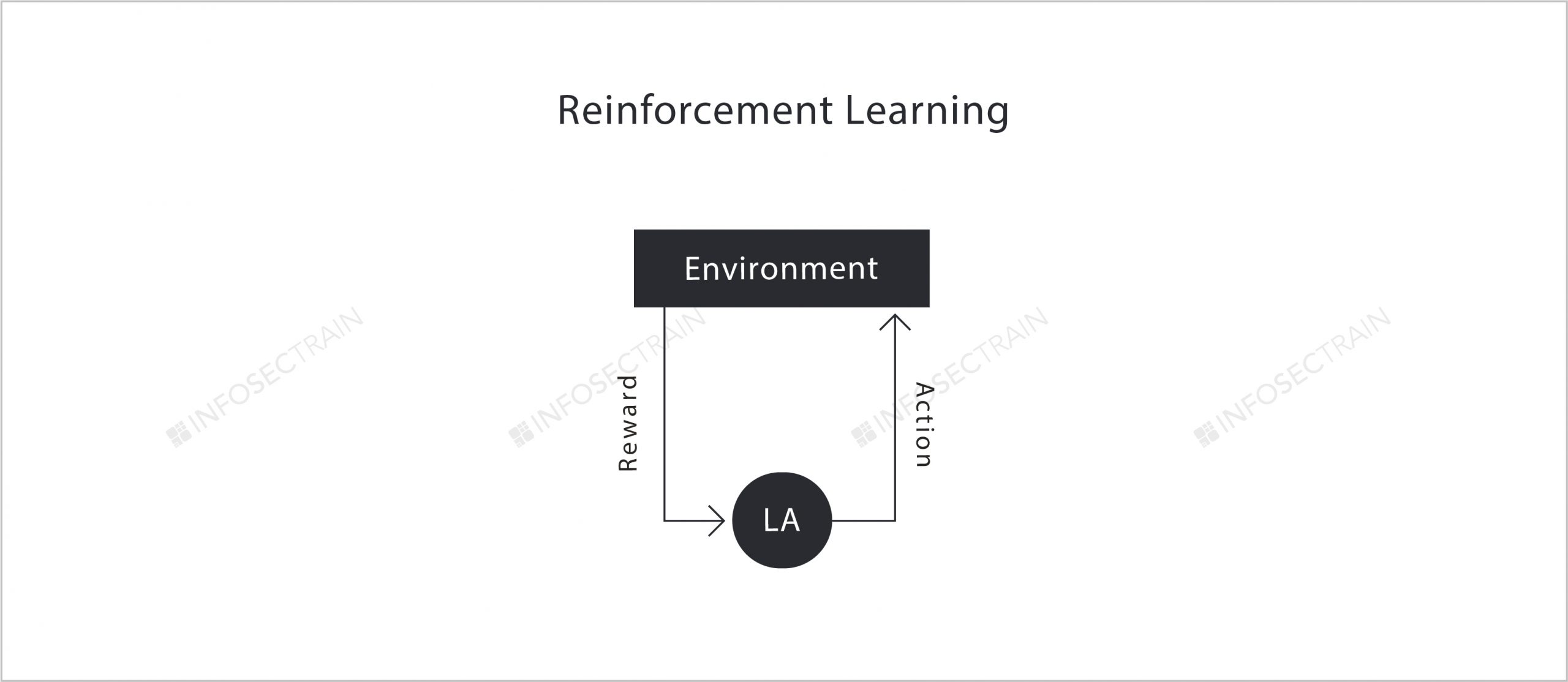
Supervised learning is similar to a classroom where the teacher is a supervisor and the student is a Learning Agent. As shown in the figure, the supervisor already consists of the desired output, and it will also expect the same or very similar output from the Learning Agent. This Learning Agent gets the training data from the environment and tries to produce the desired output. And once the Learning Agent produces the output, it is sent to the adder, and if the output is the same as the desired output, the supervisor accepts it, or else it will be sent back to the Learning Agent by the adder. This process will be repeated until the Learning Agent produces the desired output. In simple terms, in machine learning, something under the supervision of a supervisor is called supervised learning.
Unsupervised learning: It is used to handle raw datasets and is primarily responsible for converting raw data into structured data. Almost every field in today’s world has a great deal of raw data, and even computers produce log files of raw data. That is why it is essential to machine learning.
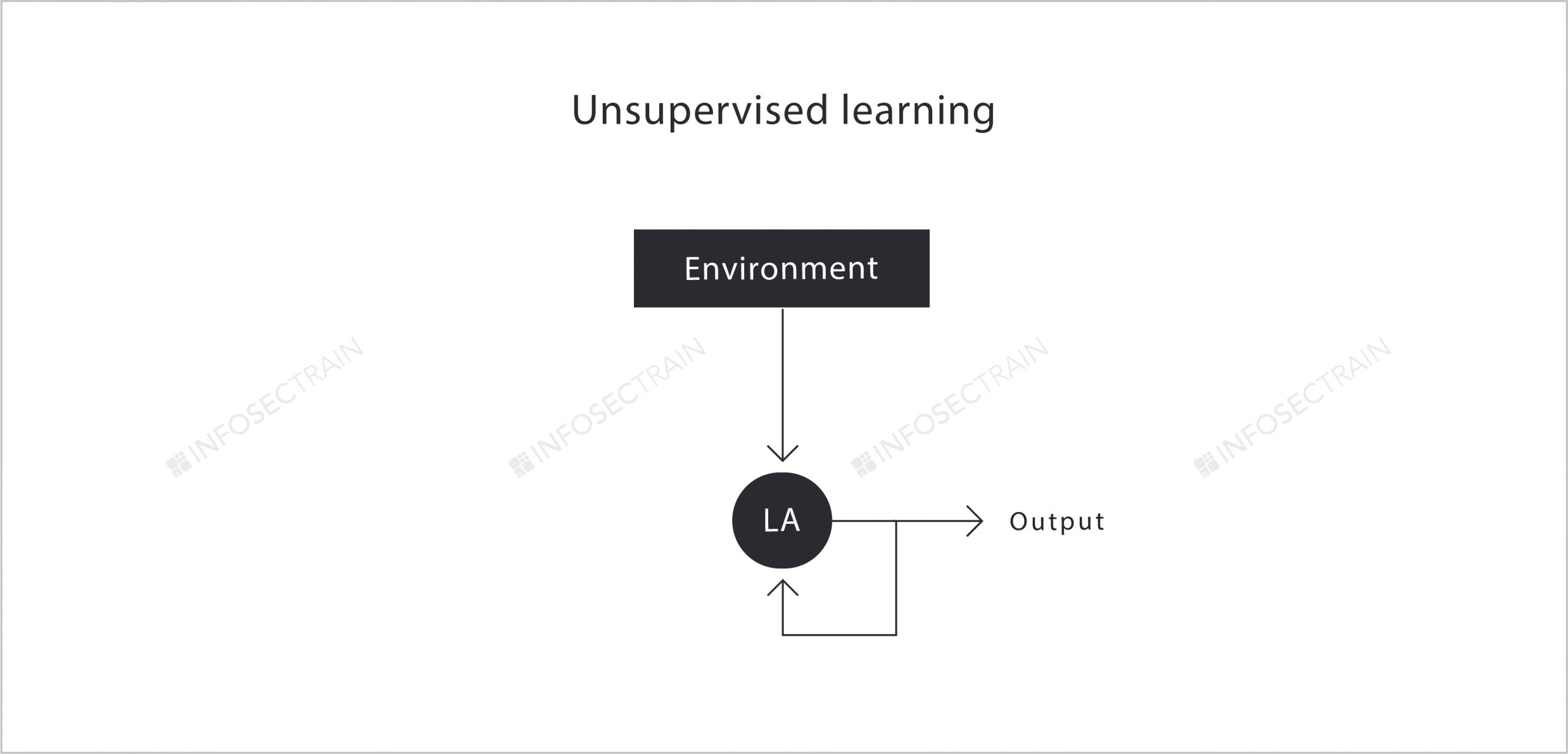
Unlike supervised learning, there is no supervisor or any desired output in unsupervised learning. The Learning Agent gets the data from the environment and tries to self-improve its output by comparing it to the previous output.
Reinforcement learning: This algorithm helps the machine learn how to make specific decisions. This is how it works: the machine is exposed to an environment in which it uses trial and error to train itself continuously. The machine uses past experience to make accurate business decisions based on past experience. The Markov Decision Process is an example of reinforcement learning.
These algorithms are further classified into the following:
Linear Regression: Linear Regression is one of the most well-known and common Machine Learning algorithms. Linear Regression is commonly used for predictive analysis, and it makes predictions for numeric or real/continuous variables like age, salary, price, sales, and so on.
This algorithm shows the linear relationship among the dependent (Y) and independent (X) variables. As Linear Regressions display the linear relationship among the variables, we can find how the dependent variable is changing with respect to the change in the independent variable.
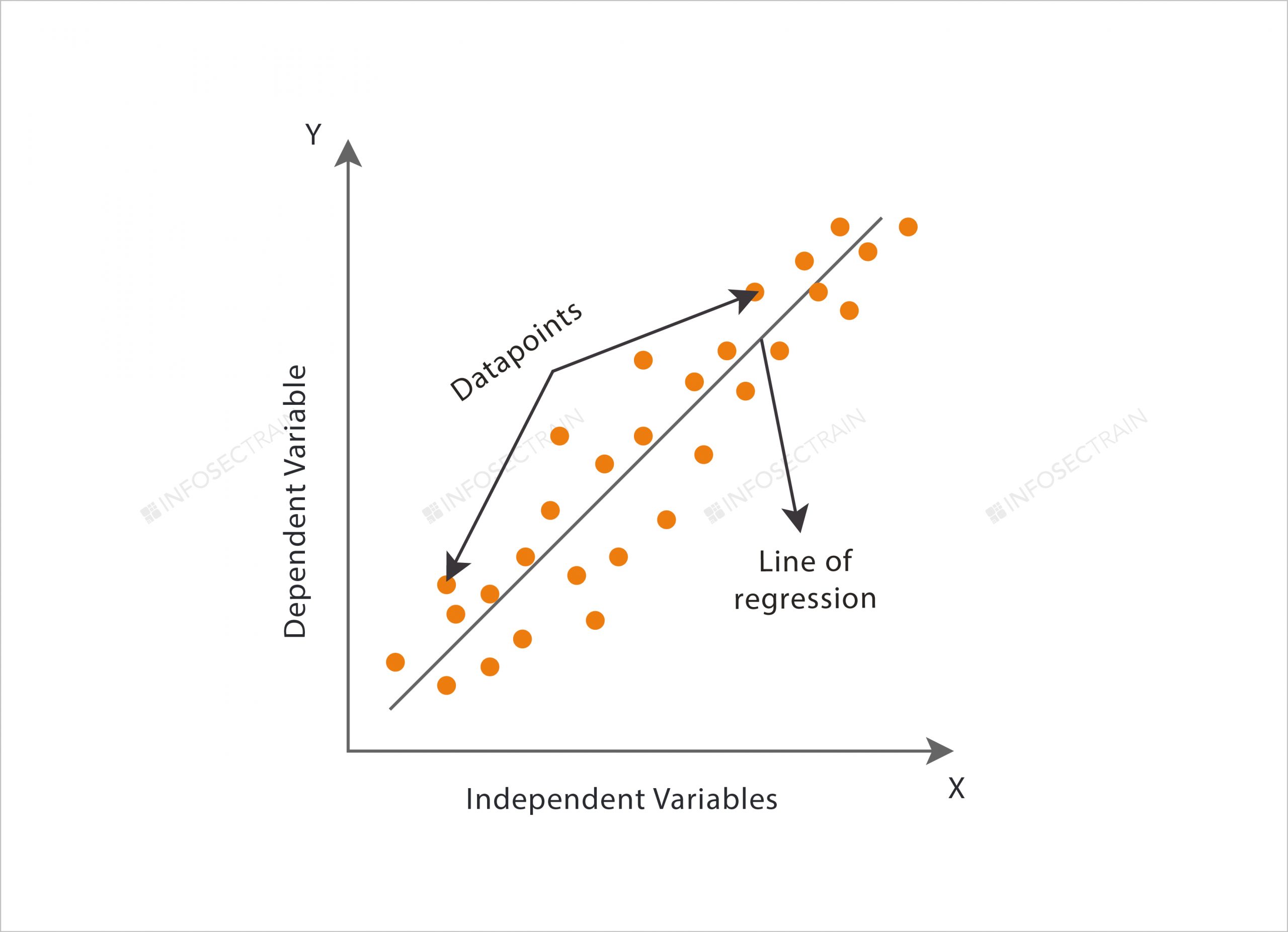
The linear regression can be represented mathematically as
y= a0+a1x+ ε
Y= Dependent Variable
X= Independent Variable
a0= Intercept of the line
a1 = Linear regression coefficient
ε = Random error
K-Nearest Neighbor (KNN) algorithm: KNN is one of the simplest supervised learning algorithms. This algorithm compares the newly added data/case to the previously existing cases and assigns the new case to that category. KNN is also known as a “lazy learner” algorithm because it does not instantly learn from the training set; instead, it keeps the dataset and executes an action on it during classification.
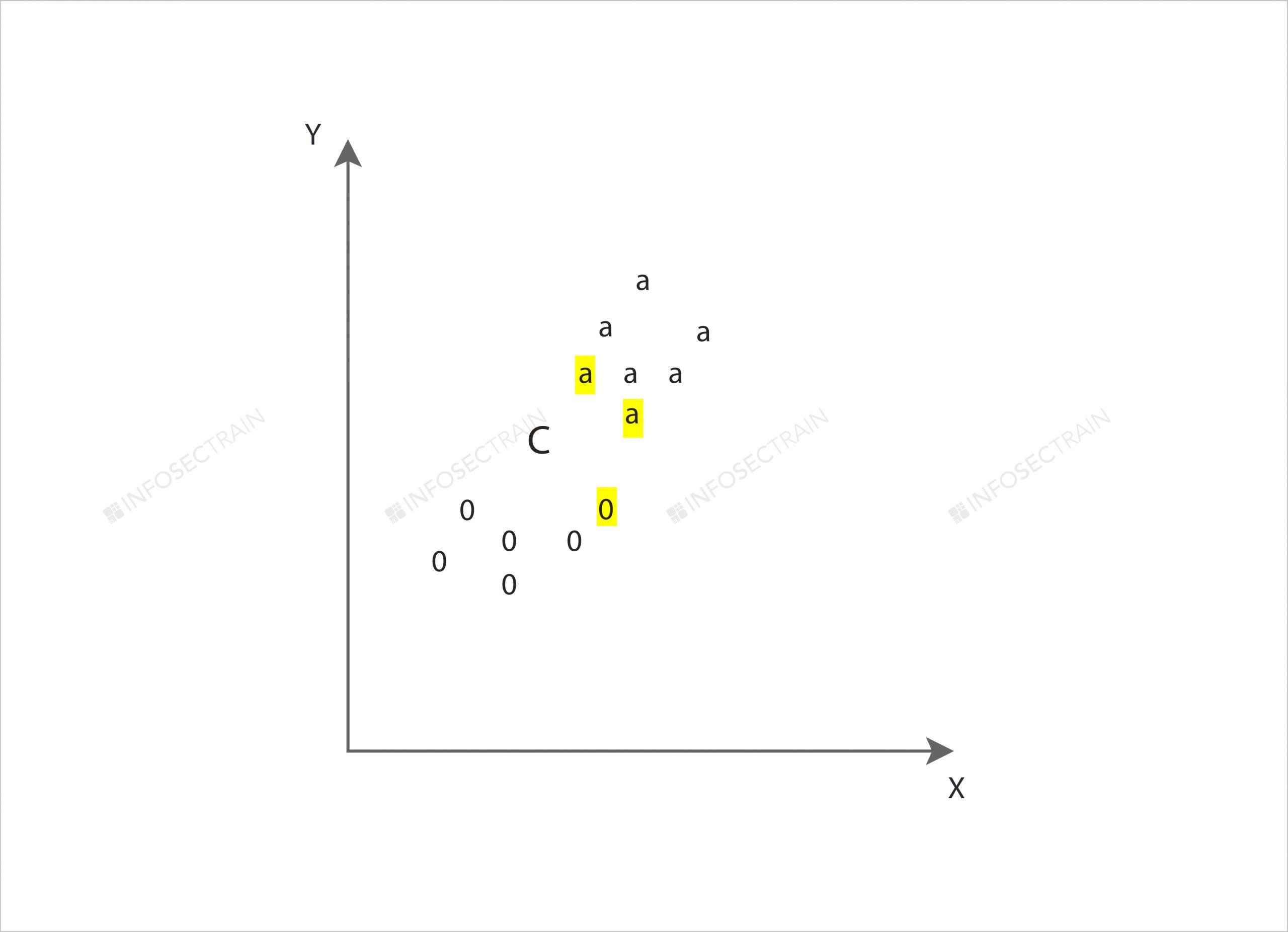
Above is a simple example to understand the KNN. Let us say, from the given N training vectors, the KNN identifies the K Nearest Neighbors of “C” regardless of the labels. Let us say
K = 3. This means we have to find the 3 Nearest Neighbors of C.
Classes = o, a
Find a class for C.
So now, as there are two “a” classes and one “o” class near C, which means two votes from a and one vote from o, C belongs to the class “a.”
One more simple example is
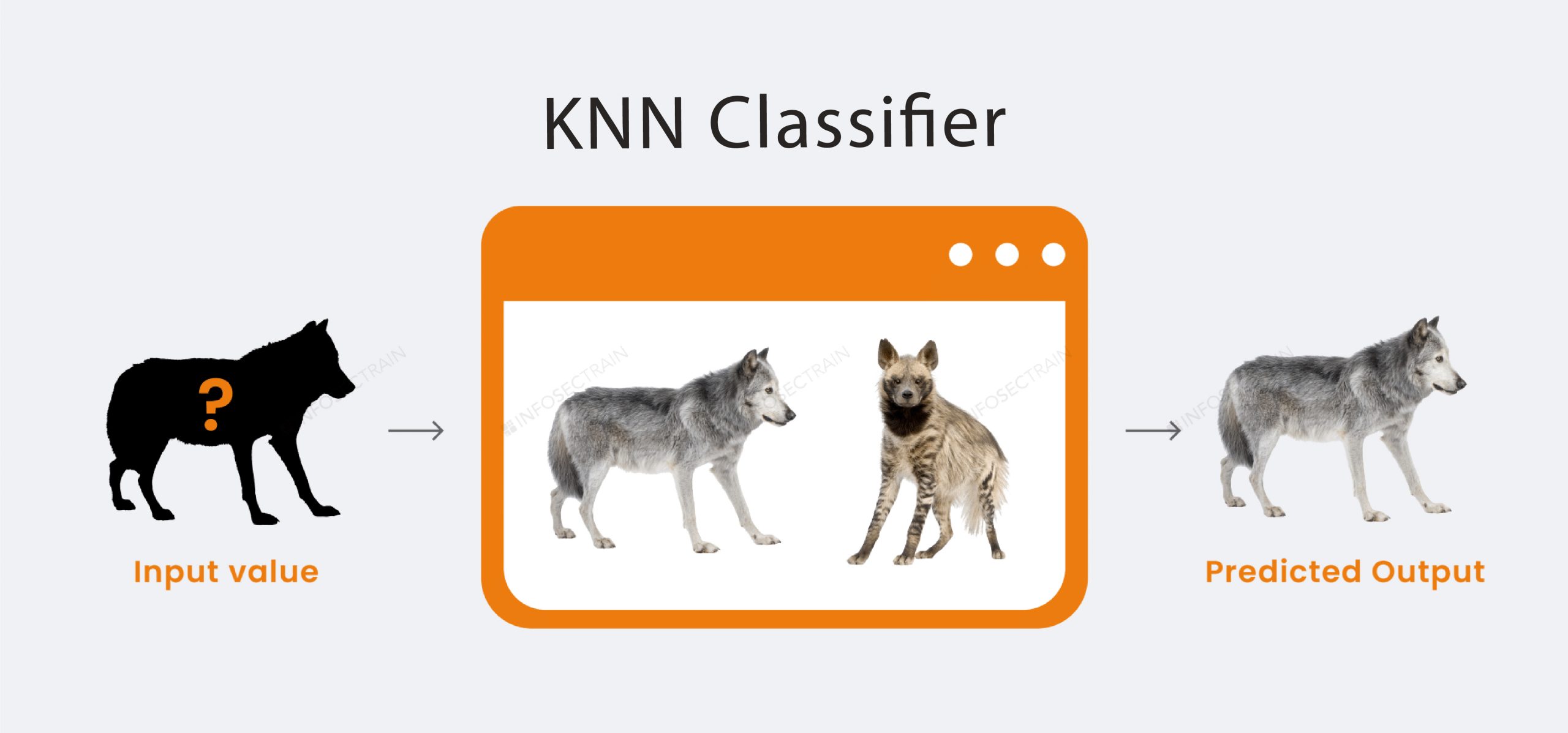
Suppose we have a picture of a creature like a wolf and a hyena, and we want to know who the creature is; we can use the KNN algorithm as this algorithm uses a similarity measure. With the help of the KNN model, we will find similar features of the new dataset to the wolf and hyena images based on those similarities. We will categorize it as either wolf or hyena.
Final words
As we are living in an age of constant technological advancement, we can predict what lies ahead by looking at how computing has grown over the years. Computer tools and techniques have been made available to the general public, which is one of the main attributes of this revolution. Since the early 2000s, data scientists have built sophisticated data-crunching machines that seamlessly execute advanced algorithms. These developments have produced stunning results. And if you are willing to become a part of this exciting and booming profession, or if you want to learn more interesting algorithms, check out the InfosecTrain website to get the best Data Science training from the experts.


Contact Us


 1800-843-7890 (India)
1800-843-7890 (India) 
