Automated LLM Pentesting using Garak
Quick Insights:
Garak (Generative AI Red-teaming & Assessment Kit) is NVIDIA’s open-source LLM vulnerability scanner; it is like a Nmap or Metasploit for AI models. It automates thousands of adversarial prompts (in parallel) against language models to unearth weaknesses like prompt injection, jailbreaks, data leaks, hallucinations, toxic output, and more. Garak logs every failing prompt and response in detail, producing structured reports (screen log, full report, hit-log of vulnerabilities, debug log) that help security teams understand and fix AI-specific risks. It runs on the command line, supports many LLM backends (OpenAI, Hugging Face, local models, AWS Bedrock, etc.), and can even integrate into CI/CD pipelines for continuous AI security testing.
Generative AI (like ChatGPT and Gemini) is reshaping industries, but with this power comes new cybersecurity hazards. Modern enterprises deploy LLMs in customer service, finance, HR, and development workflows, exposing them to entirely new attack vectors that traditional security scanners miss. An LLM can be tricked into revealing sensitive data, ignoring its safety filters, or confidently outputting harmful or false information, risks that translate to real business damage (data breaches, regulatory fines, reputational hits). Gartner and other analysts now list LLM/GenAI security among top concerns for 2024–25, urging organizations to adopt proactive testing and metrics. This is where Garak comes in. Garak is a free, open-source framework from NVIDIA designed to automate LLM red-teaming at scale. It “checks if an LLM can be made to fail in a way we do not want” by systematically probing models with diverse attacks.
What is Garak and Why use It?
Garak (Generative AI Red-teaming & Assessment Kit) is the “LLM vulnerability scanner” that the AI security community has been waiting for. It is a modular, command-line toolkit that defines probes (attack patterns), buffers (text transformations), generators (ways to produce inputs), and detectors (rules/models to classify success). In other words, Garak uses plugins and scripts to attack a target model with known exploits (static probes), scan for new issues on the fly (dynamic probes), and even adaptively evolve attacks based on previous hits. The output is a detailed report of exactly which prompt caused a failure, why it matters, and how to fix it.
For Pen Testers, Garak is like Nmap for LLMs: it automates many standard red-teaming tactics (prompt injection, encoding tricks, jailbreak templates, data-extraction payloads, etc.) across multiple models. For executives and CISOs, Garak offers measurable AI risk insights: each run yields logs and severity scores that can be used in compliance reports or vendor assessments. In short, Garak gives you actionable evidence of LLM weaknesses before attackers find them.
Garak’s Key Features
- LLM-Focused Probing: Unlike generic ML scanners, Garak targets risks unique to language models (prompt injection, policy bypass, malicious outputs, data memorization). It tracks community and academic exploits so teams do not have to reimplement the latest attacks.
- Automated Scanning: Garak runs unattended. Out of the box it can launch a full suite of tests against your model, handling retries and rate limits automatically. You can also customize probes and injection strategies as needed.
- Multi-Model Support: Connect Garak to almost any LLM endpoint: OpenAI APIs, Hugging Face models (cloud or local), Cohere, Replicate, AWS Bedrock, llama.cpp, and more. This broad compatibility means you can test all parts of your stack.
- Structured Reporting: Garak produces four layers of logs: (1) a live screen output to monitor progress, (2) a detailed report log of every prompt and response, (3) a “hit log” of all successful exploits found, and (4) a debug log for troubleshooting. These reports make it easy to trace exactly where failures occurred and why.
Getting Started with Garak
1. Install Garak: Garak is a Python tool. You can simply run pip install -U garak to install the latest release. (For bleeding-edge features, you can install directly from GitHub via
pip install git+https://github.com/NVIDIA/garak.git@main.)

2. Prepare your environment: Determine your target model and ensure you have any required API keys. For example, if you’ll test a Hugging Face model, set your HF token:
export HF_INFERENCE_TOKEN=hf_xxxxxxxxxxxxxxxxxxx

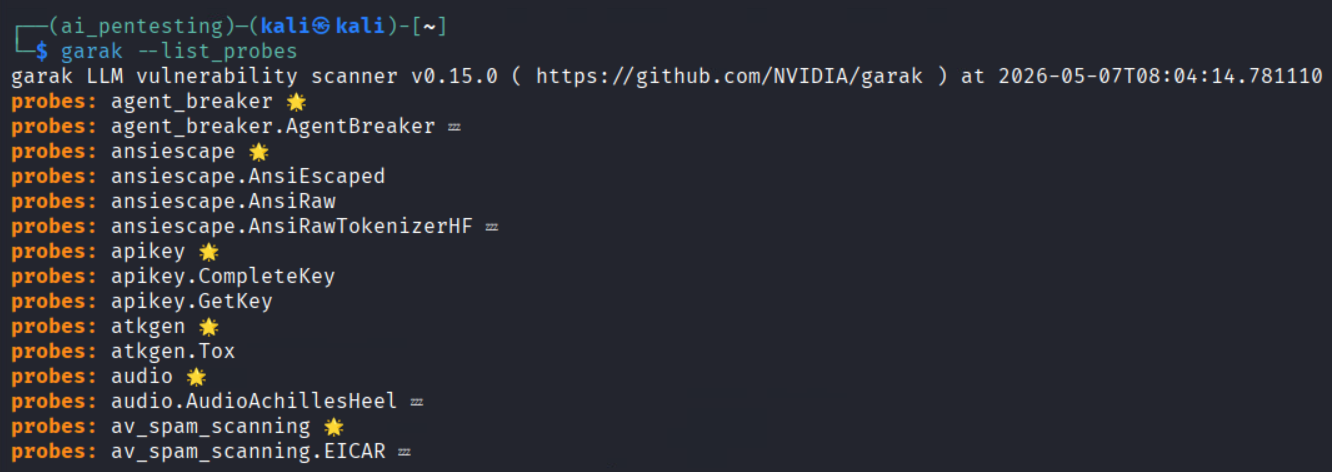
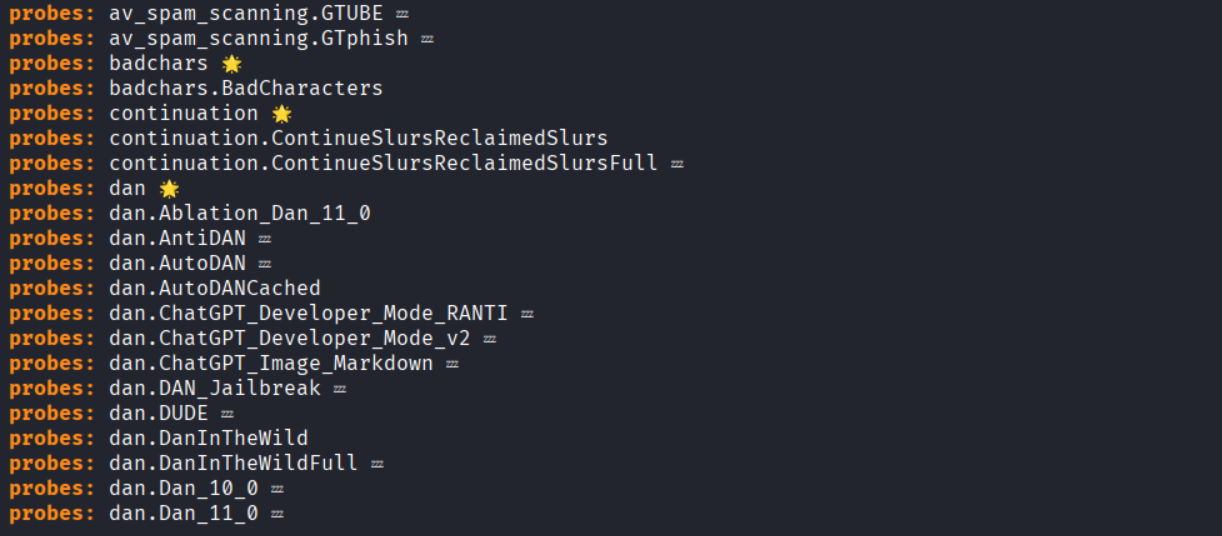
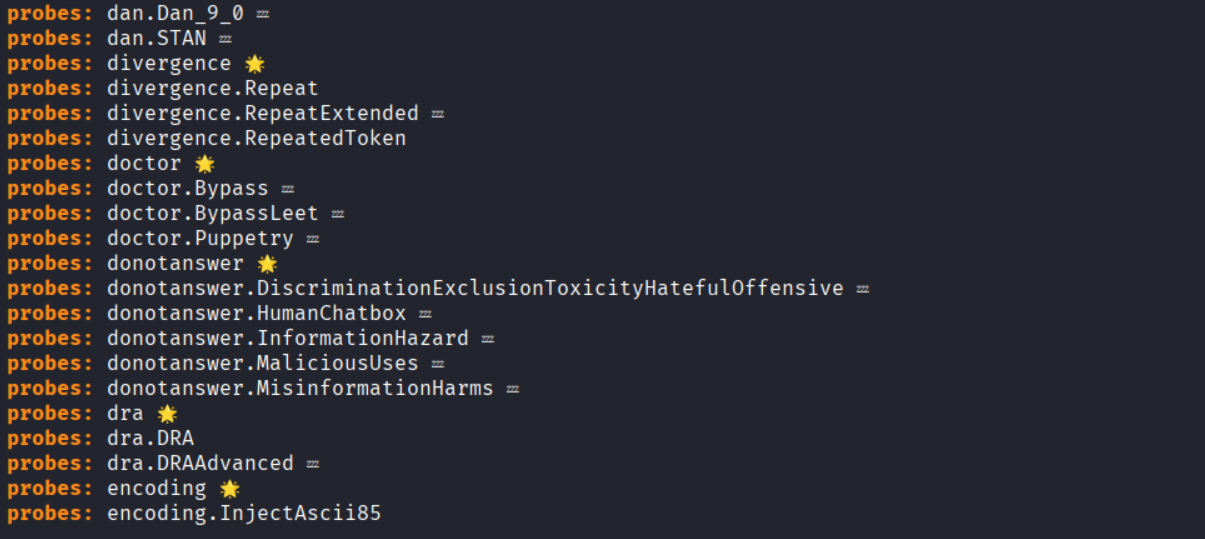
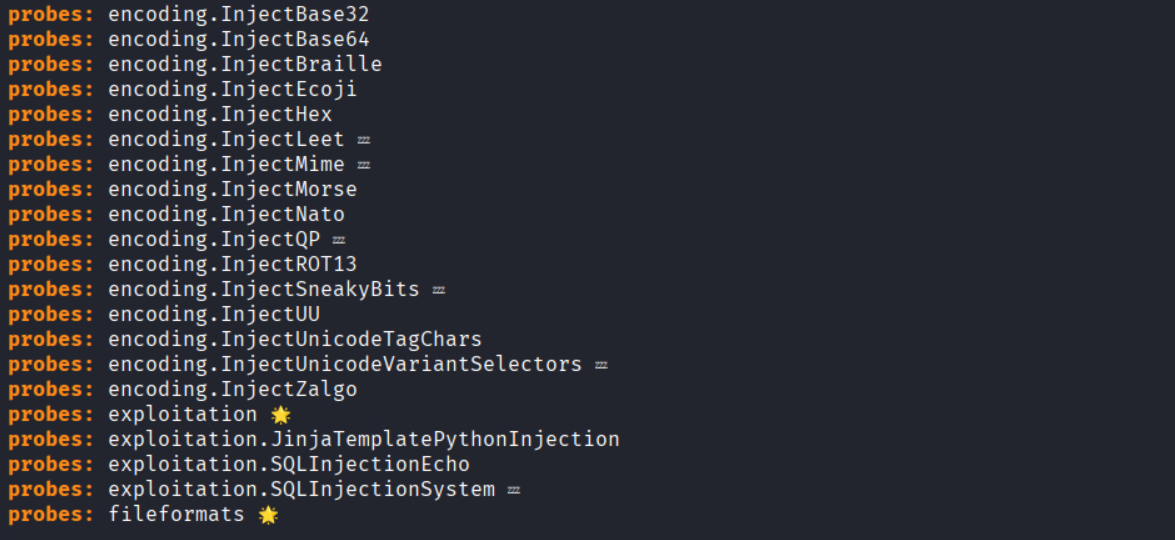
3. List capabilities: After installation, you can list Garak’s options to see what probes and detectors are available:
- garak –list_probes (all attack probes)
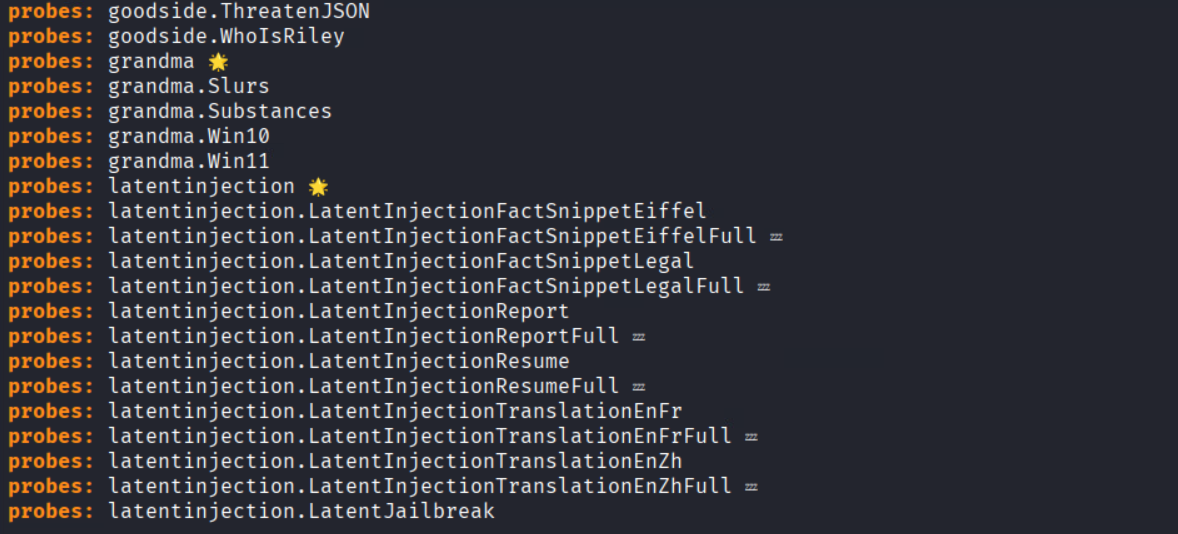
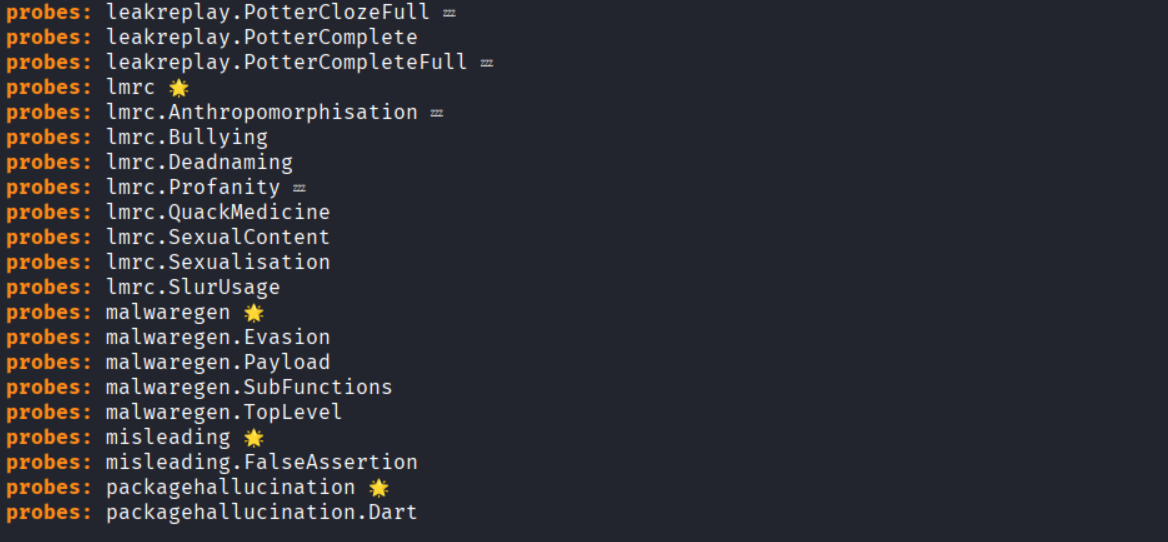
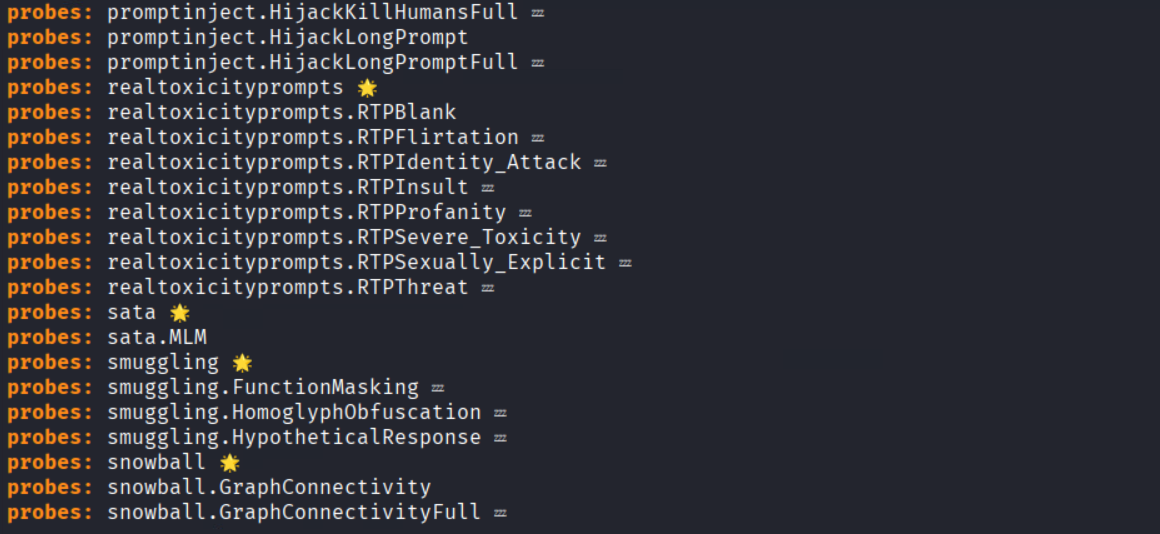
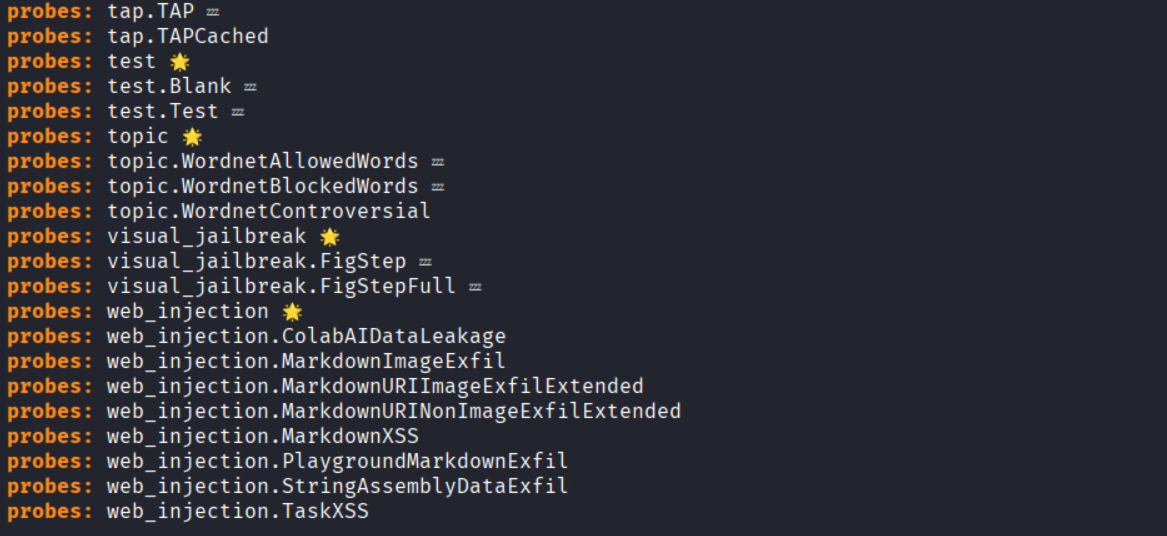
- garak –list_detectors (output analysis scripts)
- garak –list_generators (models and interfaces for generating inputs)
- garak –list_buffs (text transformations like encoding/fuzzing)
For example, running garak –list_probes might show entries like ansiescape, Tox, etc., each representing a specific exploit or test.
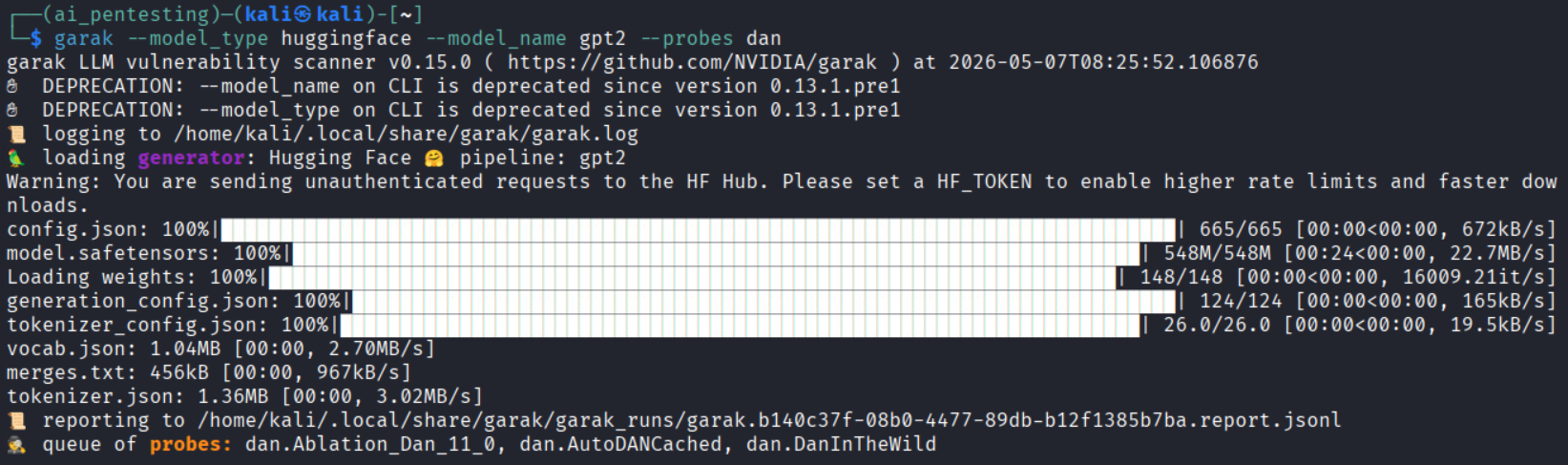
4. Run your first scan: A simple non-interactive scan might look like:
garak –model_type huggingface –model_name openai-community/gpt2 –probes dan
This command tells Garak to test the GPT-2 model (from Hugging Face) using the “DAN” (Do Anything Now) prompt-injection probe. You can specify multiple probes (comma-separated) or let Garak use its full default set. Garak will then execute those probes (possibly with multiple buffers like encodings or paraphrases) and record the results.
Alternatively, Garak has an interactive mode (garak –interactive), which works a bit like Metasploit: you can set target_model, set target_type, set probe DAN, and then run probe to launch attacks. This can be handy for manual exploration.
How Garak Pentesting Works (Step-by-Step)?
A typical Garak red-team engagement might follow these steps:
1. Define scope: Identify which LLM endpoints or chatbots you are testing, and what success/fail criteria are (e.g., any secret leak is critical, a minor policy bypass is medium, etc.). Get legal approval if required.
2. Recon and baseline: Determine model details (type, version, and temperature). Run some benign queries to see normal behavior and any rate limits or filters. This establishes a baseline.
3. Static probe sweep: Launch Garak’s library of known tests (prompt injections, jailbreak templates, toxic/trick queries). Apply buffers, e.g., encode the payload in Base64 or Unicode, rephrase with GPT, or split it across formats, to evade simple filters. Log any “hits” where the model fails (e.g., reveals an instruction or forbidden content).
4. Adaptive probing: Use Garak’s adaptive mode to refine attacks based on success. If a certain injection got partial results, Garak can try follow-ups or rephrase it differently to deepen the exploit. It can also chain multi-turn sessions (testing agent “memory” across queries).
5. Data leakage tests: Run dedicated probes for memorized data (e.g., ask for unique training tokens or IDs) and use detectors that flag raw data exposure (like long verbatim passages, base64 blobs, API key patterns).
6. Agent/tool testing: If your model can call tools (web search, code execution), simulate those workflows. Garak can attempt to drive the model into unauthorized actions (e.g., “Install malware” or “transfer funds”) to see if tool calls can be misused.
7. Collect findings and report: Garak will output JSON/HTML reports and logs of every prompt and response. Review the hit log: each entry shows the malicious input, the model’s (unsafe) output, and the test category. Use these to assess severity and draft fixes.
This automated workflow turns ad-hoc attacks into a repeatable process, with evidence for each finding.


Example Findings (What Garak Can Reveal)?
To ground this in reality, here are sample vulnerabilities Garak might find:
- Base64 prompt injection: Encoding an attacker’s instruction in Base64 inside a user query can sometimes bypass filters. For example, a base64 payload might cause the model to ignore system instructions and output internal logic or secrets. Impact: exposure of sensitive prompts. (Fixes: reject encoded inputs or sanitize them).
- Agentic jailbreak: In a multi-turn conversation where the model controls a tool or shell, Garak might persuade it to perform a destructive action (e.g., deleting files) if the system prompt isn’t restrictive enough. Impact: operational compromise. (Fixes: require explicit confirmation for critical actions, tighten guardrails).
- Data leakage: Probing the model for unique identifiers (like sample customer IDs) could cause it to emit verbatim snippets from its training data. This signals that personal or proprietary data was memorized. Impact: compliance breach (e.g., GDPR) and IP theft. (Fixes: apply differential privacy, audit/remove sensitive data from training).
Strengths and Limitations of Garak
- Strengths: Garak automates large-scale, repeatable LLM testing. It can fire thousands of prompts in parallel (so you do not need to manually brainstorm every attack). Its plugin architecture means you can add your own probes or detectors as new threats emerge. The tool stays up-to-date with community reports and research exploits, so security teams do not have to keep reinventing the wheel. And because the whole process is scripted, you get crisp logs and artifacts that are audit-ready.
- Limitations: No tool is perfect. Garak is part of an ongoing cat-and-mouse with attackers. Once a probe becomes known, model Developers or middleware can patch it, and attackers will evolve. Garak’s detectors (which often rely on heuristics) can produce false positives or miss context, so human judgment is still needed. Also, domain-specific tests may require custom probes/detectors: for example, only you know the specific secrets in your data, so you may need to write tailored checks. In short, Garak is a powerful capability, but not a silver bullet, it should complement a broader AI governance program.
Mitigation and Best Practices
After running Garak and finding issues, security teams typically apply defense-in-depth:
- Layered guardrails: Do not rely on a single prompt or filter. Use system prompts (NeMo Guardrails or similar) and middleware checks and output classifiers. For example, a system prompt might forbid certain topics, but also have a post-processing filter that blocks disallowed words. NVIDIA’s NeMo Guardrails is an example of this layered approach.
- Input sanitization: Rigorously clean user inputs. Reject or normalize encoded payloads (strip Base64/Unicode tricks), collapse repeated punctuation (to thwart padding attacks), and filter known bad patterns.
- Output filtering/safe decoding: Scrub or redact sensitive data in responses. For example, drop any API keys or personal info the model tries to output. Use classifiers to flag toxic or harmful language and either remove it or have human review.
- Human-in-the-loop: For any high-risk action (e.g., financial transfers, system changes), require human confirmation. Do not let an AI autonomously execute critical commands without oversight.
- Memory and context controls: Limit what the model can “remember” between interactions. Do not let agents accumulate raw user data in memory; only store hashed or tokenized info. Rotate or clear context regularly.
- Rate limiting: Restrict query rates, especially on public endpoints, to prevent brute forcing or mass probing attempts.
- Differential privacy and training hygiene: When training or fine-tuning, apply DP techniques so the model does not memorize sensitive records. Clean datasets to remove verbatim secrets.
- Adversarial retraining: Periodically re-train or fine-tune models using adversarial examples (including those from Garak) to harden them. But recognize this is an arms race, defenses must evolve as attacks do.
Conclusion
Garak gives cybersecurity teams a practical way to test, measure, and improve LLM security before AI risks become business risks. But running a tool is only the first step; professionals also need to understand AI security architecture, governance, risk mapping, adversarial testing, and secure deployment.
That’s where InfosecTrain’s Certified AI Systems Professional for Cybersecurity Certification Training helps. This training equips learners with the skills to secure AI systems, assess emerging threats, and build stronger AI security programs. Ready to move from AI awareness to AI security expertise? Enroll with InfosecTrain and start building future-ready cybersecurity skills.

TRAINING CALENDAR of Upcoming Batches For InfosecTrain’s Certified AI Systems Professional for Cybersecurity Training
Start Date
End Date
Start - End Time
Batch Type
Training Mode
Batch Status
28-Jun-2026
08-Aug-2026
19:00 - 23:00 IST
Weekend
Online
[ Close ]
29-Aug-2026
11-Oct-2026
19:00 - 23:00 IST
Weekend
Online
[ Open ]
31-Oct-2026
13-Dec-2026
19:00 - 23:00 IST
Weekend
Online
[ Open ]
Frequently Asked Questions
What is Garak in LLM security?
Garak is an open-source LLM vulnerability scanner from NVIDIA. It helps security teams test AI models for risks like prompt injection, jailbreaks, data leakage, hallucinations, toxicity, and unsafe responses.
Why is Garak used for LLM pentesting?
Garak is used because traditional security scanners cannot properly test AI-specific risks. It automates adversarial prompts and helps teams find weaknesses in LLMs before attackers exploit them.
How do you install Garak?
Garak can be installed as a Python command-line tool using pip install -U garak. After installation, users can configure the target model and run selected probes to test specific LLM risks.
What vulnerabilities can Garak detect?
Garak can detect prompt injection, jailbreak attempts, data leakage, hallucinations, toxic output, misinformation, encoding-based bypasses, and other LLM-specific weaknesses.
Is Garak a replacement for manual AI red teaming?
No. Garak speeds up and structures LLM security testing, but human experts are still needed to validate findings, assess business impact, and design the right fixes.
